Am Montag war ich an eine Diskussion über zukünftige Features des Literatur-Verwaltungsprogramms Lit-Link (das noch einiges mehr als Literatur-Verwaltung beherrscht) eingeladen. Dabei ging es unter anderem auch um die Frage, in welche Arbeitsumgebung die Literaturverwaltung eingebunden werden soll:
- in ein Textverarbeitungsprogramm (à la EndNote – meiner Ansicht ein Ansatz aus der Vor-Web-Ära)
- in einen Browser (also webbasiert – ein aktueller Ansatz des web 2.0)
- in einer Literatur-Verwaltungssoftware (die als Schnittstelle agiert)
Jeder beantwortet diese Frage gemäss seinen Arbeitsgewohnheiten und -überzeugungen wohl anders. Feststeht jedenfalls, dass alle drei Lösungsvarianten sich aufeinander zu bewegen, dass mit anderen Worten Import- und Exportschnittstellen wichtig werden.
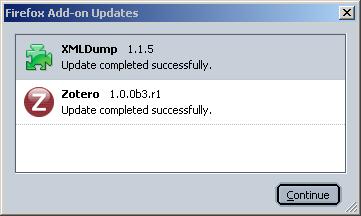
Wie viel da an Integration schon geboten wird, zeigen zwei kleine Beispiele. Zotero habe ich hier schon kurz vorgestellt, mich damals aber über mangelnde Zeit beklagt, das Ding zu testen, Prompt habe ich ein wesentliches Merkmal übersehen. Zotero ist ein FireFox-Plugin, das auf einer Website automatisch erkennt und mit einem Symbol (1) anzeigt, ob Daten vorliegen (2), die in die Literatur-Verwaltung übernommen werden können (3). Ein Klick, und die Daten sind in der Zotero-Datenbank.

Ähnliches leistet das Firefox Plugin XML-Dump (hier die Installations-Seite bei Litlink), das mit Lit-Link zusammenarbeitet – aber auch für andere Literatur-Verwaltungslösungen geeignet ist, da es das Austausch-Format XML produziert. Das XML-Dump-Plugin stöbert ebenfalls auf Knopfdruck (1) in der angezeigten Web-Seite Informationen auf, die auf eine bibliographische Angabe hinweisen, und bereitet diese als XML auf (2) und legt diese an einen frei wählbaren Ort ab.

In den Einstellungen kann auch spezifiziert werden, welche Angaben im Text wie interpretiert werden soll.

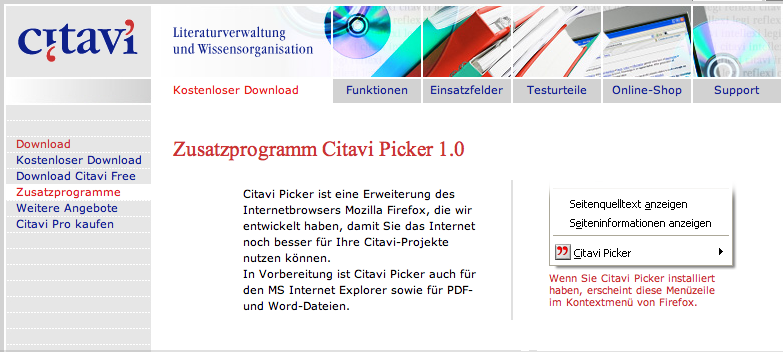
Auch die (Windows only-)Literaturverwaltung citavi bietet eine solche Web-Integration, die aber anders funktioniert: hier werden markierte Daten extrahiert, bzw. in bestimmten Literatur-Datenbanken abgefragt und die dort gelieferten Ergebnisse in die Datenbank aufgenommen.

Was fehlt? Eine Literaturverwaltung nur auf dem Netz? Gibt es auch: zum Beispiel Bibsonomy (auch schon hier kurz erwähnt), das stark an den Social Bookmark-Dienst de.licio.us erinnert (von wo auch Einträge samt Tags importiert werden können, habe ich mal gemacht). Dort können auch Literaturangaben erfasst und ge-„taggt“ werden. Auch Import und Export in verschiedenen Formaten sind möglich; so habe ich Zotero-Einträge im BibTex-Format exportiert und in Bibsonomy eingelesen.
P.S.: natürlich gibt es noch weitere gute und sinnvolle Literatur-Verwaltungsprogramme. Wer will, darf seine Favoriten in die Kommentare schreiben.
Übersicht: HOK Lesen: Suchen und Finden